How to Easily Extract All URLs from Your Sitemap Using Python
Hello, SEOs!
It’s been a while since my last post I’ve been revamping my setup and got myself a comfy new chair, which is perfect for coding those technical SEO solutions.
Today, I’ve got a useful script to share with you, perfect for anyone managing a site. Imagine you want to extract all URLs from your sitemap.xml file quickly.
Maybe you’re analysing your site’s content, or perhaps you need to keep track of which pages are active. With Python, you can do this in just a few lines of code.
Why Use Python to Read Sitemap URLs?
For anyone working with websites, sitemap.xml files are a must-have for search engines to crawl all your pages. Instead of manually going through each URL, this Python script will handle the job by reading the sitemap, parsing the XML, and saving all the URLs for easy access.
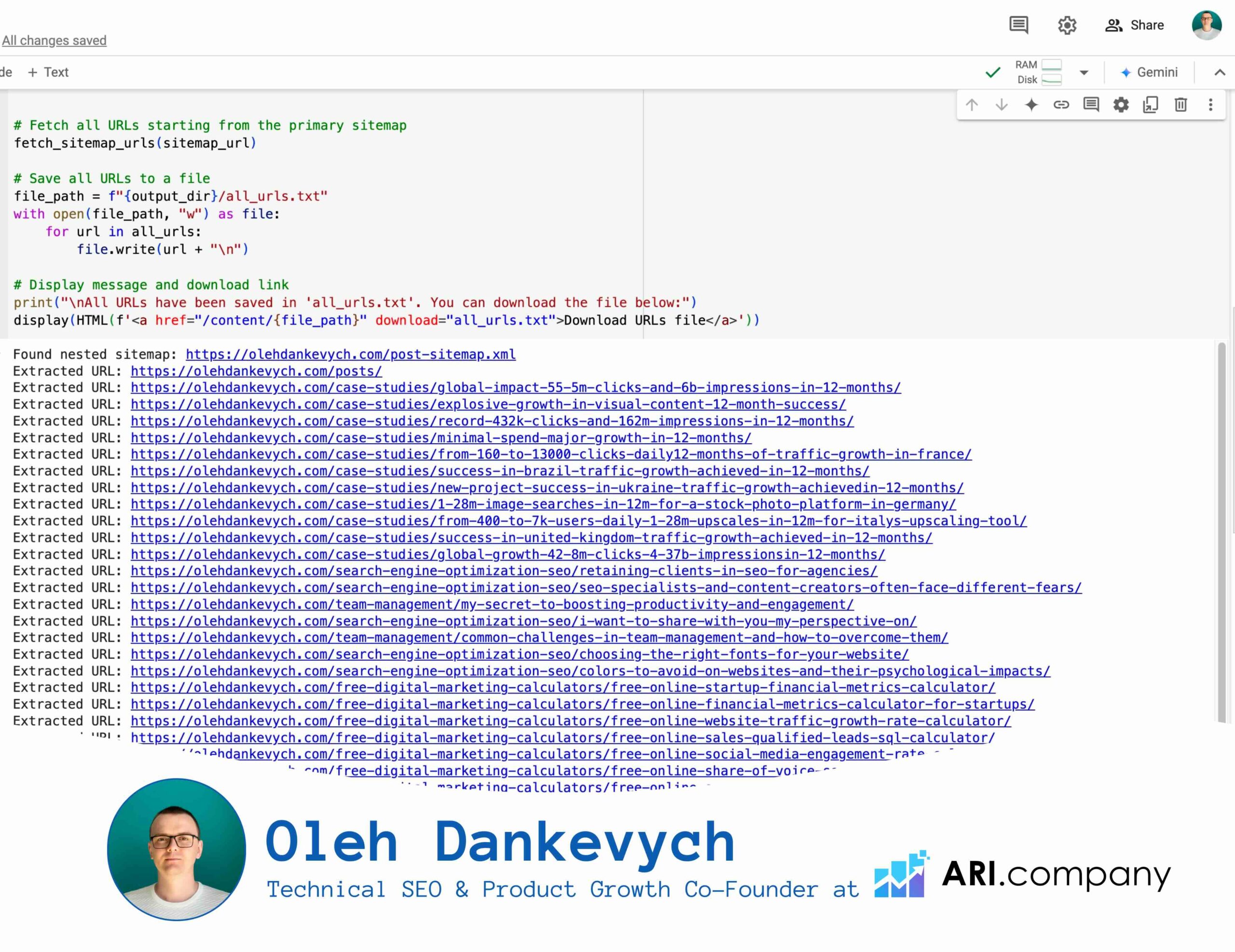
What This Code Does:
1. Downloads the Sitemap: It pulls your sitemap from the web and checks if it’s accessible.
2. Parses the XML: With Python’s XML parser, it searches for <loc> tags (where the URLs are stored).
3. Extracts and Saves URLs: Finally, it writes all the URLs into a text file, urls.txt, for you to access easily.
Give it a try and let me know how it works for you!
P.S. I will upgrade it and soon it will have more detailed checks.
I have placed the updated code for extracting URLs from sitemap.xml and its nested sitemaps on Google Colab. You can access it and run the code directly from this link: How to Easily Extract All URLs from Your Sitemap Using Python
****
Enjoy this? ♻️ Repost it to your network and follow Me for more.